 “阿爾法狗”Zero跳出圍棋 多領域挑戰人類
“阿爾法狗”Zero跳出圍棋 多領域挑戰人類“阿爾法狗”Zero跳出圍棋 多領域挑戰人類
近日,DeepMind在arXiv發表論文表示,AlphaGo Zero已開始嘗試完成其他任務,其現已具有通用性。

DeepMind團隊目前一直以推動人工智能的界限,開發可以學會解決任何復雜問題而不需要學習的程序為自身使命。在今年年初,其已經引入了一種“強化學習”(reinforcement learning)的AI技術來增強AlphaGo,這個技術不需要人類輸入信息,只需要制定規則,它就可以自己獲得超人一般的技法。
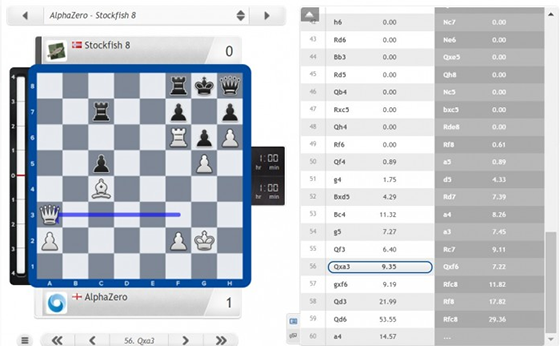
DeepMind舉了兩個例子,表示AlphaGo Zero可以自己學習國際象棋和將棋,只需要24小時,它就可以達到擊敗世界冠軍的水平。(這兩個游戲相比較圍棋而言,較為簡單)
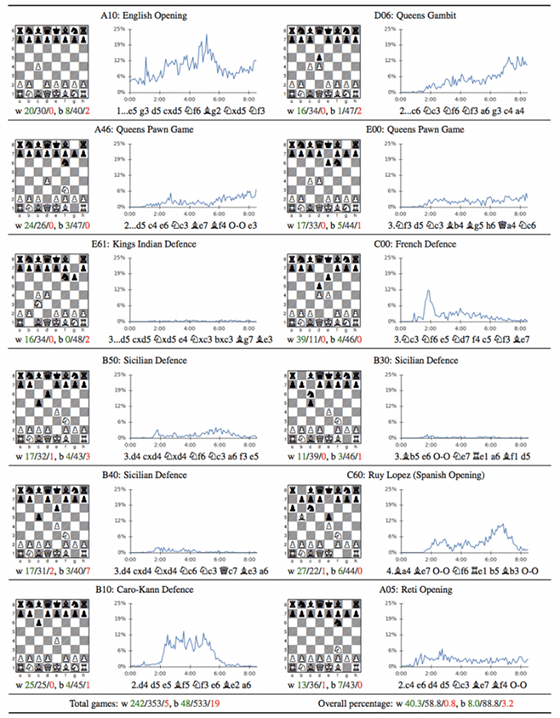
AlphaGo Zero的通用性可使其掌管各種不同的游戲,這無疑是可以讓機器學習能力越來越強,但是目前其還無法在策略性游戲(如星際爭霸)超過人類,但是相信以其恐怖的學習能力那一天也不會太遙遠。
點個贊796



熱點資訊
 華為nova 15系列手機發布!超大杯搭載前后雙紅楓影像,配置堪稱豪華拖把上周
華為nova 15系列手機發布!超大杯搭載前后雙紅楓影像,配置堪稱豪華拖把上周 蘋果首款折疊屏iPhone Fold機模出爐:橫置攝像頭,iPad mini的親兄弟白貓5 天前
蘋果首款折疊屏iPhone Fold機模出爐:橫置攝像頭,iPad mini的親兄弟白貓5 天前 小米17 Ultra官宣圣誕節發布,想要徠卡可樂標得加錢?Viking上周
小米17 Ultra官宣圣誕節發布,想要徠卡可樂標得加錢?Viking上周 毫無隱私!300元監控軟件上熱搜,能躲過殺毒軟件監視員工拖把4 天前
毫無隱私!300元監控軟件上熱搜,能躲過殺毒軟件監視員工拖把4 天前 牙膏擠爆?iQOO Z11 Turbo或將搭載驍龍8gen5,成“同檔最強”拖把上周
牙膏擠爆?iQOO Z11 Turbo或將搭載驍龍8gen5,成“同檔最強”拖把上周 榮耀WIN手機再度預熱,不僅10000mAh巨無霸電池,還內置了風扇! 二楠6 天前
榮耀WIN手機再度預熱,不僅10000mAh巨無霸電池,還內置了風扇! 二楠6 天前 第三方耳機也能秒連蘋果iOS 26.3 國內再次無緣!姜維6 天前
第三方耳機也能秒連蘋果iOS 26.3 國內再次無緣!姜維6 天前 光圈換光學變焦?小米17 Ultra徠卡APO長焦鏡頭細節曝光Napoleon Chan6 天前
光圈換光學變焦?小米17 Ultra徠卡APO長焦鏡頭細節曝光Napoleon Chan6 天前 又有新處理器?曝OPPO K Turbo系列新機高配版將用天璣9500s拖把5 天前
又有新處理器?曝OPPO K Turbo系列新機高配版將用天璣9500s拖把5 天前



 滬公網安備 31010702005758號
滬公網安備 31010702005758號
發表評論注冊|登錄