 牙膏、馬甲不爭氣 谷歌自研芯片超CPU/GPU15-30倍
牙膏、馬甲不爭氣 谷歌自研芯片超CPU/GPU15-30倍牙膏、馬甲不爭氣 谷歌自研芯片超CPU/GPU15-30倍
谷歌正在自研芯片以加速其機器學習算法,這已經不是什么秘密。早在2016年5月的I/O開發者大會上,谷歌就透露過這些芯片,稱之為TPU(Tensor Processing Units),但當時除了表明它是圍繞其TensorFlow機器學習框架而設計優化的產品外,并未公布有關于這一芯片的更多細節。如今,谷歌終于發布了一些TPU研究的成果。

其實,如果對這方面感興趣,在谷歌論文(Google's paper)中是可以找到關于TPU的一些運作細節的。盡管如此,谷歌自身的基準測試結果,依然聚集了整個行業的目光。這一結果為谷歌評估自己的芯片,以此為前提,谷歌的公布的情況為:TPU在執行谷歌常規的機器學習工作負載方面,相較于一個標準的CPU/GPU組合,Intel Haswell CPU搭配Nvidia K80 GPU,平均要高出15倍至30倍之多。更重要的是,TPU的每瓦特性能(TeraOps/瓦特)達到了一般CPU/GPU組合的30倍至80倍,如果采用了新的內存,這一數值還將更高。
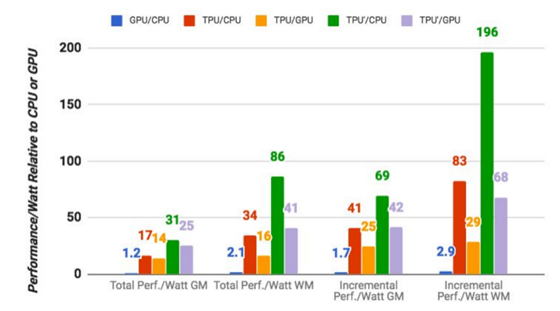
值得注意的是,這些數字都是關于生產使用中的機器學習模型,而非新創模型。谷歌還指出,雖然很多構架師針對卷積神經網絡(例如,用于圖像識別的特定類型神經網絡)優化了這一芯片,但這些網絡只占其數據中心工作負載的5%左右,而大部分應用程序使用的是多層感知器(multi-layer perceptrons)。這也就意味著,TPU的應用場景并不單一,未來的前景十分廣闊。
谷歌表示,早在2006年,他們就已經開始研究如何在數據中心使用GPU、FPGA和自定義ASIC,這實際上也是TPU的本質。然而,當時并沒有那么多的應用程序真的能受益于這種特殊的硬件,因為當時的硬件足夠處理數據中心的負載。谷歌的文章中提到:“在2013年,我們預計深度神經網絡(DNN)將會大有所為,以至于我們數據中心的計算需求將增加一倍,這個需求如果采用傳統CPU來解決,將會異常昂貴。因此,我們開始了一個高度優先的項目,以快速生成用于推演的自定義ASIC(并購買了現成的GPU來進行訓練)。”谷歌的研究人員說,“這樣做的目的是將GPU的性能提高10倍以上。”
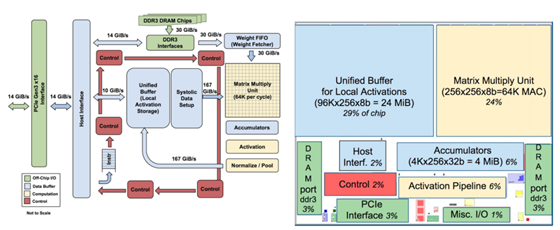
不過,谷歌很有可能并不會對外提供TPU。可盡管如此,還是會有很多人從谷歌的一些設計中學到些東西,得到些靈感,“設計出更出色的接班人”也并非不可能。或者至少,能給牙膏廠英特爾、馬甲廠英偉達帶來些壓力也是好的。



熱點資訊
 思銳光學P&I直擊:土星V2全球首發,這支“豎拍神器”為何備受關注?Amelia4 天前
思銳光學P&I直擊:土星V2全球首發,這支“豎拍神器”為何備受關注?Amelia4 天前 榮耀Power3配置曝光,超10000mAh巨無霸電池顧亭亭4 天前
榮耀Power3配置曝光,超10000mAh巨無霸電池顧亭亭4 天前 疑似華為Mate 90系列配置曝光:搭載新一代麒麟處理器,自研2億像素主攝顧亭亭4 天前
疑似華為Mate 90系列配置曝光:搭載新一代麒麟處理器,自研2億像素主攝顧亭亭4 天前 友商陸續跟進!傳vivo也在評估方形前攝,預計用于超大杯拖把4 天前
友商陸續跟進!傳vivo也在評估方形前攝,預計用于超大杯拖把4 天前 給全民影像打好穩固基礎!閃迪全系列移動存儲亮相P&I 2026拖把4 天前
給全民影像打好穩固基礎!閃迪全系列移動存儲亮相P&I 2026拖把4 天前 雅迪尊界夢幻聯動,雅迪董事長一次性入手三臺尊界 S800咻咻4 天前
雅迪尊界夢幻聯動,雅迪董事長一次性入手三臺尊界 S800咻咻4 天前 專訪飛牛fnOS創始人朱挺:AI時代,創作者需要的不只是更大的NASAmelia3 天前
專訪飛牛fnOS創始人朱挺:AI時代,創作者需要的不只是更大的NASAmelia3 天前 P&I SHANGHAI 2026回顧:國產品牌再度發力,新膠卷、新鏡頭皆有Napoleon Chan3 天前
P&I SHANGHAI 2026回顧:國產品牌再度發力,新膠卷、新鏡頭皆有Napoleon Chan3 天前 P&I探展:相機、鏡頭、AI PC,今年的影像展都有哪些新變化? 顧亭亭3 天前
P&I探展:相機、鏡頭、AI PC,今年的影像展都有哪些新變化? 顧亭亭3 天前



 滬公網安備 31010702005758號
滬公網安備 31010702005758號
發表評論注冊|登錄